Abstract
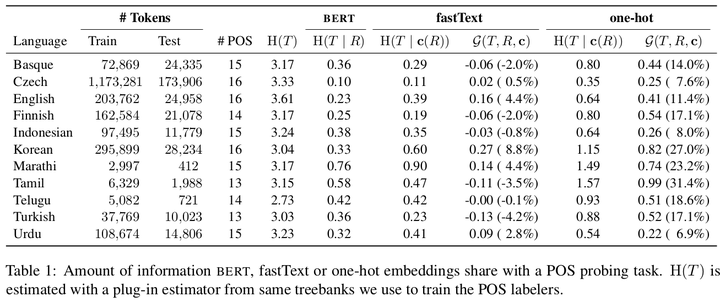
The success of neural networks on a diverse set of NLP tasks has led researchers to question how much these networks actually know about natural language. Probes are a natural way of assessing this. When probing, a researcher chooses a linguistic task and trains a supervised model to predict annotations in that linguistic task from the network’s learned representations. If the probe does well, the researcher may conclude that the representations encode knowledge related to the task. A commonly held belief is that using simpler models as probes is better; the logic is that simpler models will identify linguistic structure, but not learn the task itself. We propose an information-theoretic formalization of probing as estimating mutual information that contradicts this received wisdom: one should always select the highest performing probe one can, even if it is more complex, since it will result in a tighter estimate, and thus reveal more of the linguistic information inhering in the contextualized representation. The empirical portion of our paper focuses on obtaining tight estimates for how much information BERT knows about both parts of speech and dependency labels, evaluating it in a set of ten typologically diverse languages often under-represented in parsing research, plus English, totalling eleven languages. We find BERT only accounts for more information about parts of speech than a traditional type-based word embedding in five of the eleven analysed languages. When we look at dependency labels, BERT does improve upon type-based embeddings in all analysed languages, but accounting for at most 12% more information.